Particle filter intro
The state estimation filtering will use the KF, PF, memberfship fitlers to fix like below.
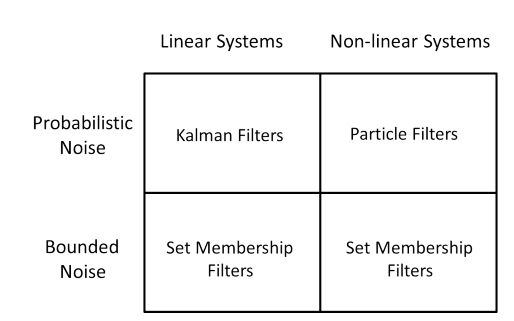
PF could be used in both linear system and non-linear system. For the linear system, it required that:
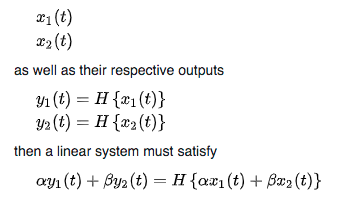
Why PF? Most of systems are non-linear, and Gaussian noise will be violated sometimes. PF uses the Monte Carlo methods to simulate the samples, according to the large number theory, as particles get large, the empirical distribution gets close to the true distribution.
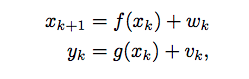
Steps
x: state variable; u: inputs; z: observations; d: data.

- Prediction:

- Update:
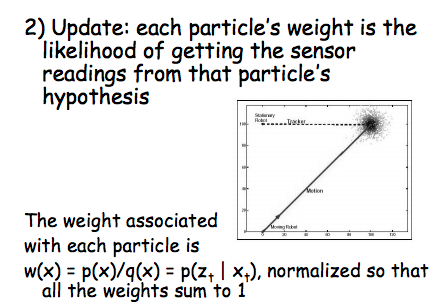
- Resample: sample importance sampling. (particle deletion; high probability in MAP not represent well; density could not represent the real pdf) Importance resampling. poster / prior with observation model.

- Output estimate state
This process could be wrote as:

Improve: Rao-Blackwellised Particle Filter
| The aim of Rao-Blackwellised Particle Filtering is to find an estimator of the conditional distribution  such that less particles will be required to reach the same accuracy as a typical particle filter. |
split the posterior probability into two sets, one could be calculated by closed form(margin probability accumlated) and other could be calculated by the PF.
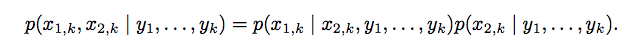
Application
-
Monte Carlo Localization in ref. 4.
Summary
- Why PF? Advantage & disadvantages.
- How to do with PF?
- Improve of PF?
Histogram filter
Another non-parameter method, and using the grid to represent the state. The formula very similar to PF.

More state estimation with parametric filters are:
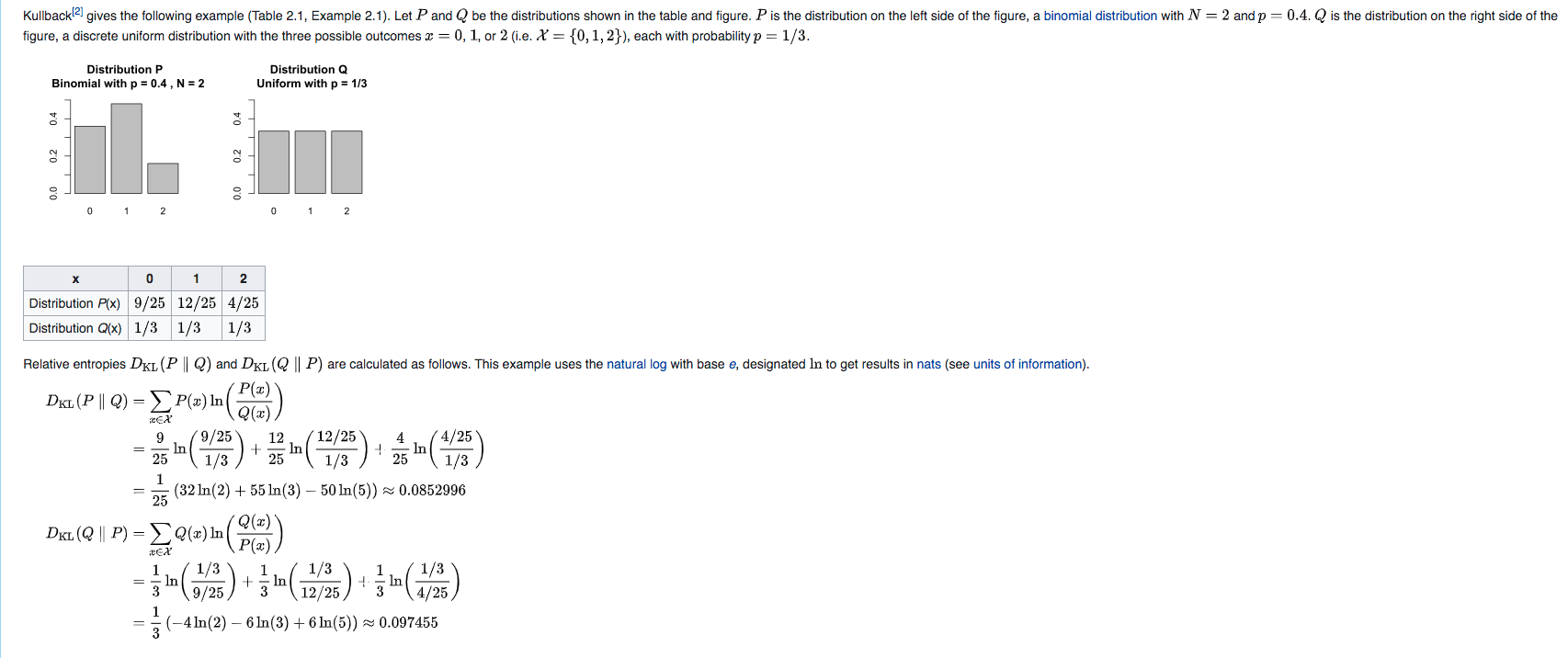
KL divergence: Consider two probability distributions 


KLD sample:
With relationship with cross-entropy:
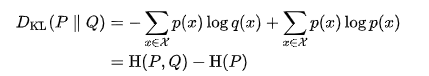
Ref: